Introduction to Big Data Analytics
Chapter 3: Spark Core
Xingang (Ian) Fang
Spark Overview
Spark is an in-memory cluster computing framework for large-scale data processing.
Key characteristics
easy to use
fast
general-purpose
scalable
fault-tolerant
Characteristics
Easy to use
Spark provides high-level APIs in Java, Scala, Python, and R
Much more concise than Hadoop MapReduce code
Fast
Spark can run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
General-purpose
While Hadoop is a platform allowing many third-party applications to run on it, Spark is a general-purpose computing engine with most essential functionalities built-in.
Spark is designed to cover a wide range of workloads such as batch applications, iterative algorithms, interactive queries, and streaming. Spark also supports third-party tools and libraries although its core components are more frequently used.
Scalable
Spark can run on clusters with thousands of nodes.
Can always add more nodes to your cluster to handle more data.
Fault-tolerant
Spark provides fault tolerance through lineage information stored in the memory.
If a partition of an RDD is lost, Spark will recompute it using the lineage information.
Automatically handle failed or slow nodes.
Spark Architecture
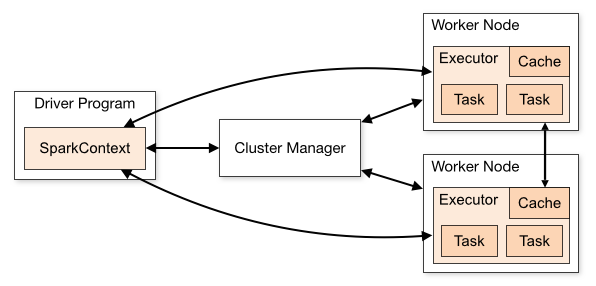
Spark Components
Worker: Computer nodes that provide CPU, memory and storage resources to a spark application.
Cluster Manager: used to acquire cluster resources for executing a job. Options: Standalone, Mesos, or YARN
Driver Program: Provides data processing code that are executed on worker nodes.
Executor: A JVM process that spark creates on each worker for an application.
Task: A smallest unit of work that spark sends to an executor.
Application Execution
Key concepts
Shuffle: Redistributes data among cluster of nodes according certain criteria.
Job: A job is a set of computations that spark performs to return results to a driver program.
Stage: A stage is a collection of tasks. Spark splits a job into a DAG (Directed acyclic graphs) of stages. Tasks that do not require a shuffle are grouped into a single stage.
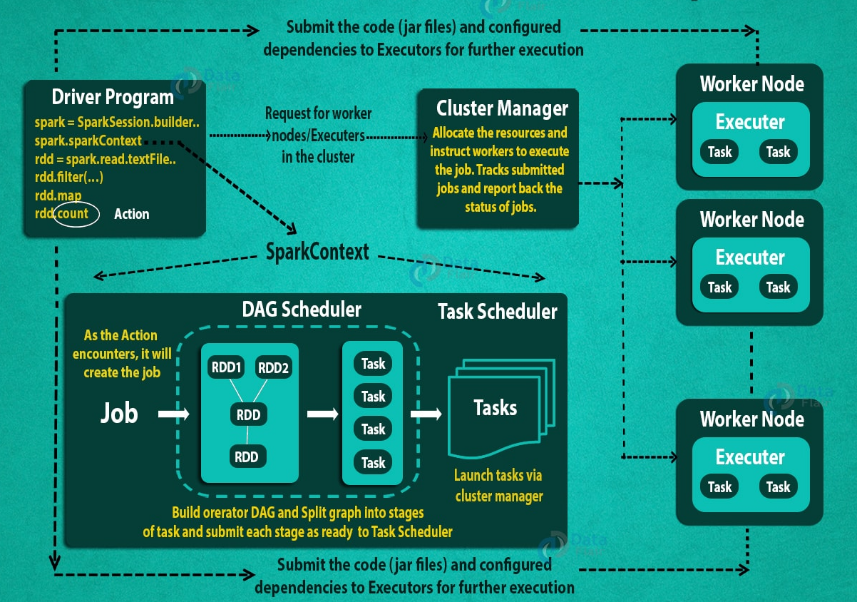
Execution flow
The driver program connects to the cluster manager to acquire resources.
Algorithms are submitted as jobs
Spark breaks the job into a DAG (directed acyclic graph) of stages; Each stage is a collection of tasks.
Stages are scheduled on executors
Executors run tasks and return results
Execution Flow
Data Source
Spark does not provide its own storage system.
It can read data from various sources
Distributed file systems: HDFS, Azure Data Lake
Object storage: Amazon S3, Azure Blob Storage, Google Cloud Storage
NoSQL databases: Cassandra, HBase, MongoDB, Couchbase
Traditional relational databases: MySQL, PostgreSQL, Oracle, SQL Server
Spark supports structured, semi-structured, and unstructured data.
Spark also supports various file formats such as Parquet, Avro, ORC, JSON, and CSV.
Data ingestion through data APIs, streaming, etc.
Spark Application Programming Interface (API)
Spark provides APIs in Java, Scala, Python, and R.
Two fundamental components
SparkContext: Entry point to any spark functionality.
RDD: Resilient Distributed Dataset, the fundamental data structure of Spark.
Spark SQL provides high-level DataFrame and Dataset APIs built on top of RDDs.
SparkContext Object
The entry point to any spark functionality.
Available as the variable
scin the spark shell.In standalone applications, you create and configure a SparkContext object.
val conf = new SparkConf().setAppName("MyApp").setMaster("spark://host:port") val sc = new SparkContext(conf)
Resilient Distributed Dataset (RDD)
RDD is the fundamental data structure of Spark to model collections of objects distributed across a cluster.
Characteristics
Immutable: Once created, an RDD cannot be changed.
Distributed: Data is distributed across multiple nodes in a cluster as partitions.
Fault-tolerant: If a partition of an RDD is lost, Spark will recompute it using lineage information.
In-memory computation: Spark stores intermediate results in memory.
Strongly typed: RDDs are strongly typed with Scala.
Interface: available as Scala abstract class with concrete implementations such as ParallelCollectionRDD, HadoopRDD, etc.
Lazy evaluation: Spark does not compute the result until an action is called.
RDD resembles local collection types in terms of operations
RDD Creation
Two ways to create RDDs
Parallelizing an existing collection in your driver program.
Using the
parallelizemethod.Only for small datasets that can fit in memory of a single node.
val data = (1 to 10000).toList val distData = sc.parallelize(data)Load data from an external storage system such as HDFS, S3, etc.
SparkContext provides methods to read data from various sources.
textFile: Read text file(s) from HDFS, S3, etc. with each line as an element.wholeTextFiles: Read text file(s) from HDFS, S3, etc. with each file as an element.sequenceFile: Read key-value pairs from Hadoop sequence files.
RDD Operations
Transformations and actions are extended concepts corresponding to map and reduce in Hadoop MapReduce.
Transformations
Create a new RDD from an existing RDD.
map is a special case that applies a function to each element of an RDD to provide another RDD with the same size.
Actions
Return an object to the driver program after running a computation on the RDD.
RDD Operations Cont.d 1
Common RDD types that require different operations
List like: RDD of a list of elements
Map like: RDD of key-value pairs
Common transformations
For normal list like RDD: map, filter, flatMap, distinct, union, intersection, subtract, cartesian, etc.
For map like RDD: mapValues, flatMapValues, keys, values, reduceByKey, groupByKey, sortByKey, etc.
Common actions
For normal list like RDD: reduce, collect, count, first, take, takeSample, takeOrdered, saveAsTextFile, etc.
For map like RDD: countByKey, collectAsMap, lookup, etc.
Lazy Evaluation
A.k.a lazy operation or call by need.
Transformations and RDD creation
Spark does not compute the result immediately.
Only lineage information is recorded.
Each worker will apply the transformation to its partition of the RDD.
Run in parallel on different workers.
Actions
Action will trigger the execution of the unfinished upstream transformations.
Requires workers to interchange data among themselves.
Cannot be easily parallelized.
Spark will optimize the execution plan before running the job.
Caching
As Spark RDDs are computed on-demand, it is possible that the same RDD is computed multiple times. To avoid this, Spark provides caching. When an RDD is cached, it is stored in memory across the nodes in the cluster. This allows subsequent actions on the RDD to be computed faster.
Two ways to cache an RDD
cachemethod: Cache the RDD in memory.persistmethod: Cache the RDD in memory or on disk
Fault tolerance: If an RDD is lost, Spark will recompute it using lineage information.
Memory management: Spark will automatically evict old data to make space for new data.
Spark Jobs
A job is a set of computations that Spark performs to return the results of an action to a driver program.
An application can have multiple jobs.
Spark breaks a job into a DAG (directed acyclic graph) of stages.
Each stage is a collection of tasks.
Tasks are grouped into stages based on the shuffle boundary.
Stages are scheduled on executors to be executed in parallel.
Shared Variable
A share-nothing model by default
Two types of shared variables
Broadcast variables: Efficiently distribute large read-only values to workers.
val broadcastVar = sc.broadcast(Array(1, 2, 3)) broadcastVar.value // can be used in every worker nowAccumulators: Aggregate values from workers back to the driver program.
val accum = sc.accumulator("My Accumulator") sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))