Big Data Processing¶
The term “data processing” in this course refers to the procedure of turning raw data from the data acquisition stage into processed data that are ready for consumption by the subsequent data analysis tasks.
Data processing is typically the most difficult and time-consuming step in the entire process due to the complexity of the raw data used in big data applications.
Numerous data processing tasks are frequently used in this stage. The most typical tasks are described in the list below.
MapReduce Paradigm¶
Overview and importance¶
The MapReduce paradigm is a popular and effective data processing technique used in Big Data processing. It allows for the distributed processing of large data sets across a cluster of computers using a simple programming model. The paradigm involves two major functions - Map and Reduce - which help break down the data processing task into smaller, manageable chunks, thereby improving the efficiency and scalability of the processing. With the exponential growth of data in recent years, the MapReduce paradigm has become increasingly important for processing Big Data, particularly for organizations dealing with large volumes of data. The paradigm offers a range of advantages, including scalability, fault tolerance, flexibility, and cost-effectiveness, making it a popular choice for data processing. However, it also poses certain challenges, such as a steep learning curve and compatibility issues with legacy systems. Despite these challenges, the MapReduce paradigm remains a critical tool in Big Data processing, and its importance is only set to grow as the demand for Big Data processing continues to increase.
Compare to traditional methods¶
MapReduce is a paradigm that is designed to process large-scale data efficiently and effectively. It is a distributed computing model that is used to process and analyze large data sets by dividing them into smaller, more manageable pieces. In contrast, traditional data processing techniques involve processing data in a sequential manner, which can be time-consuming and inefficient for large data sets.
Advantages¶
One of the key advantages of MapReduce over traditional data processing techniques is its scalability. MapReduce can process vast amounts of data by dividing it into smaller chunks and processing them in parallel across a cluster of computers. Traditional data processing techniques, on the other hand, cannot handle large data sets in a distributed manner and require all data to be processed on a single machine.
MapReduce also offers fault tolerance, ensuring that if a single machine in the cluster fails during processing, the remaining machines can continue to process the data without losing any information. Traditional data processing techniques, on the other hand, may not have this level of fault tolerance and can lose data in case of a hardware failure.
Another advantage of MapReduce is its flexibility. MapReduce provides a simple programming model, making it easier for developers to write code to process large data sets. In contrast, traditional data processing techniques require complex code to process large data sets, which can be difficult and time-consuming to develop.
Finally, MapReduce is also cost-effective. With MapReduce, organizations can use commodity hardware, reducing the overall cost of processing large data sets. Traditional data processing techniques may require expensive hardware to process large data sets, making it cost-prohibitive for many organizations.
Phases of MapReduce¶
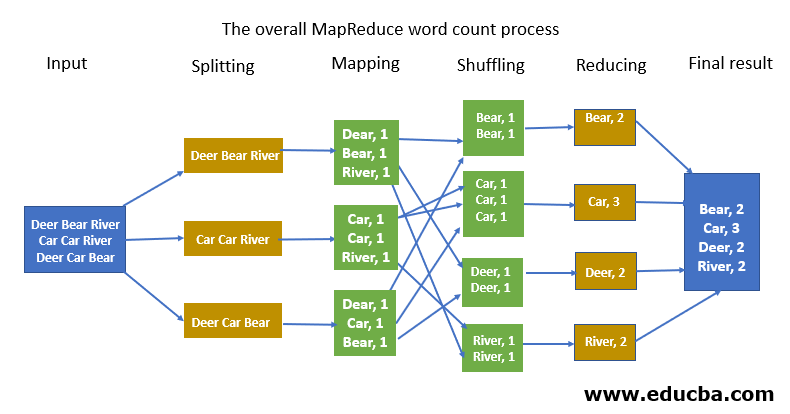
The MapReduce paradigm consists of three phases that work together to process large-scale data efficiently and effectively. These three phases are the Map phase, Shuffle and Sort phase, and Reduce phase.
Map phase: the input data is divided into smaller subsets and processed in parallel across multiple nodes in the cluster. Each node executes the Map function on its subset of the input data and produces a set of key-value pairs as output. The Map function transforms the input data into a format that can be processed by the Reduce function.
Shuffle and Sort phase: the key-value pairs generated by the Map function are sorted and partitioned based on their keys. The sorted data is then transferred to the nodes where the Reduce function will be executed. This phase ensures that all the key-value pairs with the same key are sent to the same node for processing by the Reduce function.
Reduce phase: the data is processed in parallel across multiple nodes in the cluster. Each node executes the Reduce function on its subset of the data and produces a set of output key-value pairs. The output of the Reduce function is stored in the distributed file system and serves as the final output of the MapReduce job.
The three phases of MapReduce work together to enable efficient and scalable processing of large data sets. The Map phase transforms the input data into a format that can be processed by the Reduce function. The Shuffle and Sort phase ensures that the data is properly partitioned and sorted based on the keys. The Reduce phase processes the data and produces the final output. By breaking down the processing of large data sets into these three phases, MapReduce enables efficient parallel processing of large data sets across a distributed cluster of nodes.
Map and Reduce Functions¶
The MapReduce paradigm is based on two key functions: the Map function and the Reduce function. These functions are used to process large data sets in a distributed and parallel manner.
The Map function is responsible for processing and transforming input data into a set of key-value pairs. It takes an input record and produces one or more key-value pairs as output. The Map function processes the input data independently and in parallel across multiple nodes in the cluster, thus enabling efficient processing of large data sets. The output of the Map function is stored in the distributed file system and passed on to the Shuffle and Sort phase.
The Shuffle and Sort phase sorts and partitions the output of the Map function based on the keys, and transfers the data to the Reduce function. The Reduce function is responsible for processing the key-value pairs generated by the Map function and producing a final output. The Reduce function takes the output of the Shuffle and Sort phase as input and performs a specific computation on the key-value pairs with the same key. It produces a set of output key-value pairs that are stored in the distributed file system.
The Map and Reduce functions together form the core of the MapReduce paradigm. The Map function transforms the input data into a format that can be processed by the Reduce function. The Reduce function performs the final computation on the transformed data and produces the output. The MapReduce paradigm enables the parallel processing of large data sets, making it an efficient and scalable method for Big Data processing.
Hadoop Ecosystem¶
Hadoop is an open-source software framework for distributed storage and processing of large datasets on clusters of commodity hardware. It is designed to handle big data, which refers to datasets that are too large or complex for traditional data processing applications. The Hadoop ecosystem is a collection of open-source tools and frameworks that work with Hadoop to enable big data processing.
Examples of key components in the ecosystem¶
Some of the key components of the Hadoop ecosystem include:
HDFS (Hadoop Distributed File System): a distributed file system that provides reliable and scalable storage for large datasets.
MapReduce: a programming model and software framework for processing large datasets in parallel across a cluster of computers.
YARN (Yet Another Resource Negotiator): a resource management layer that schedules and manages resources in a Hadoop cluster.
Hive: a data warehousing and SQL-like query language that allows users to analyze large datasets stored in Hadoop using SQL-like syntax.
Pig: a high-level platform for creating MapReduce programs used to process large datasets.
Spark: a fast and general-purpose cluster computing system that can run data processing tasks in memory.
HBase: a distributed, scalable, NoSQL database that provides random access to big data stored in Hadoop.
Mahout: a machine learning library for building scalable and distributed machine learning applications.
Oozie: a workflow scheduler system to manage Apache Hadoop jobs.
The first three are core components and the rests are optional. Some components such as Spark can be either deployed under Hadoop or in stand-alone mode.
Example of MapReduce in Hadoop¶
The famous word counting example in Hadoop using Java. Here is the mapreduce example from the official Hadoop documentation.
Suppose we have a text file containing a list of words, and we want to count the frequency of each word in the file.
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
The MapReduce job consists of two main parts: the mapper and the reducer. We also need a driver to run the mapper and reducer.
Mapper: In the mapper, we take the input text file and split it into individual words. For each word, we emit a key-value pair where the key is the word itself and the value is an integer 1.
Reducer: In the reducer, we receive the key-value pairs emitted by the mapper. We group together all the values associated with each key and add them up to get the total count for that word. We then emit a final key-value pair where the key is the word and the value is the total count.
Driver: In the driver code, we set up the configuration for the MapReduce job, specifying the input and output file paths, the mapper and reducer classes, and the output key and value types. We also set the combiner class, which is an optional optimization that runs on the output of the mapper before it is sent to the reducer. Finally, we run the job and wait for it to complete.
Spark¶
Apache Spark is an open-source distributed computing system that is designed to process large-scale data and perform real-time analytics. It was initially developed at UC Berkeley’s AMPLab in 2009 and later became an Apache Software Foundation project in 2013.
Spark is designed to be faster and more efficient drop-in replacement of Hadoop MapReduce. It provides in-memory processing and a more expressive and concise programming model. It soon grew into a more comprehensive data processing framework. Spark provides a unified platform for batch processing, SQL queries, stream processing, machine learning, and graph processing.
While Spark can run independently, it can also be run on top of Hadoop Distributed File System (HDFS) and can be integrated with other Hadoop components, such as YARN and HBase. Spark can also leverage Hadoop’s distributed file system and resource management capabilities, allowing it to run on large Hadoop clusters.
Components¶
Spark is a powerful open-source big data processing framework that provides a range of components for distributed data processing, machine learning, and streaming data analysis. Here are some of the key components of Spark:
Spark Core: The core engine of Spark that provides the basic functionality of the framework, including distributed task scheduling, memory management, and fault-tolerance. It includes the Resilient Distributed Datasets (RDDs) API, which is the fundamental data structure of Spark.
Spark SQL: A module of Spark that provides a SQL-like interface for working with structured and semi-structured data. It includes the DataFrame API, which allows users to manipulate structured data in a distributed environment.
Spark Streaming: A module of Spark that enables real-time processing of streaming data. It can consume data from various sources such as Kafka, Flume, and Twitter, and process it in real-time.
MLlib: A library of Spark that provides a scalable implementation of various machine learning algorithms for classification, regression, clustering, and collaborative filtering. It includes tools for feature extraction, transformation, and selection.
GraphX: A library of Spark that provides a scalable implementation of graph processing and analysis. It includes various algorithms for graph processing, including PageRank, connected components, and triangle counting.
PySpark: A package of Spark that enables users to interact with Spark from Python programming language.
SparkR: A package of Spark that enables users to interact with Spark from R programming language.
Structured Streaming: A high-level API of Spark that provides a unified programming model for batch and streaming data processing. It allows users to process data in real-time using Spark’s SQL and DataFrame APIs.
External Libraries¶
Resource manager
Baseline stand-alone mode: Spark can run in a stand-alone mode without any external resource manager.
YARN: Yet Another Resource Negotiator, a resource management layer that schedules and manages resources in a Hadoop cluster.
Kubernetes: An open-source container orchestration platform that Spark can use as a cluster manager for deploying and scaling applications.
Storage
Spark does not have its own storage system. It can work with various storage systems, including:
Distributed file systems
HDFS: Hadoop Distributed File System
DBFS: Databricks File System
ADLS: Azure Data Lake Storage
Object store
Amazon S3: Simple Storage Service
Google Cloud Storage
Azure Blob Storage
NoSQL database
Apache Cassandra: A distributed NoSQL database
Apache HBase: A distributed, scalable, NoSQL database
Relational database
MySQL
PostgreSQL
Oracle
MS SQL
Comparison to Hadoop MapReduce¶
Spark and Hadoop MapReduce are both distributed computing frameworks designed to process big data. However, there are some significant differences between the two. Here are a few key differences:
Processing Speed: Spark is generally faster than Hadoop MapReduce due to its in-memory processing capabilities. Spark can cache data in memory, while Hadoop MapReduce reads and writes data to disk for every iteration, which can slow down processing.
Ease of Use: Spark provides a more user-friendly API than Hadoop MapReduce. Spark’s high-level APIs, such as RDDs and DataFrames, are more intuitive and easier to use than Hadoop MapReduce’s lower-level APIs.
Real-Time Processing: Spark is better suited for real-time processing than Hadoop MapReduce. Spark Streaming and Structured Streaming provide real-time processing capabilities, while Hadoop MapReduce is primarily designed for batch processing.
Machine Learning: Spark has a built-in machine learning library called MLlib, which provides scalable implementation of various machine learning algorithms. In contrast, Hadoop MapReduce does not have a built-in machine learning library.
Storage: Hadoop MapReduce relies on the Hadoop Distributed File System (HDFS) for storage, while Spark can use various storage systems such as HDFS, Amazon S3, and Apache Cassandra.
Overall, Spark provides a more efficient and user-friendly framework for big data processing than Hadoop MapReduce. While Hadoop MapReduce is still widely used for batch processing, Spark’s real-time processing capabilities and built-in machine learning library make it a more versatile framework for big data processing and analytics.
Data APIs¶
Spark provides three sets important data APIs for processing and analyzing big data: RDD, DataFrame, and Dataset. Here’s a comparison of these three data APIs:
RDD (Resilient Distributed Datasets):
RDD is the basic unit of data in Spark.
RDD is an immutable distributed collection of objects that can be processed in parallel across a cluster of machines.
RDDs are resilient and fault-tolerant, which means they can recover from machine failures automatically.
RDDs are primarily used for batch processing and provide a simple and flexible API for data processing.
RDDs do not have a schema, which means they can handle unstructured and semi-structured data.
DataFrame:
DataFrame is a distributed collection of data organized into named columns.
DataFrame is similar to a table in a relational database, with a schema that describes the data types of each column.
DataFrames are optimized for processing large-scale structured and semi-structured data and provide a high-level API for data processing.
DataFrames can be integrated with Spark SQL, enabling users to perform SQL queries on their data.
DataFrames are an abstraction built on top of RDDs, providing better optimization and performance for structured data processing.
Dataset:
Dataset is a strongly typed distributed collection of objects that was introduced in Spark 1.6.
Dataset combines the advantages of RDDs and DataFrames, providing type safety and performance optimizations.
Datasets provide a high-level API for data processing and can be used with both structured and unstructured data.
Datasets are primarily used for machine learning and data science applications.
Datasets provide better optimization and performance than RDDs, especially for structured data processing.
In summary, RDD is the most basic data structure in Spark, while DataFrame and Dataset are higher-level abstractions that are optimized for structured and semi-structured data processing. RDDs only provide flexibility and fault-tolerance, while DataFrames and Datasets provide even better performance and optimization for structured data processing. Understanding the differences between these data structures is important for choosing the right tool for the job in big data processing and analytics.
Note
I will focus on the RDD programming in this course because both DataFrame and Dataset are built on top of RDD. At the same time, as a high-level API designed to work with structured data, DataFrame and Dataset are closer to standard SQL and do not match our goal of learning big data processing much.
Thus, we will focus on RDD programming in this course to learn how to process unstructured (e.g. raw text) and semi-structured (e.g. JSON) data and generate structured data (e.g. CSV) for further analysis.
PySpark Code Examples¶
Below are example written in Python. It work with Spark though the PySpark components. All three data APIs are demonstrated here.
# Import SparkSession
from pyspark.sql import SparkSession
# Create a Spark Session
spark = SparkSession.builder.master("local[*]").getOrCreate()
# Create an RDD from a list of numbers
rdd = spark.sparkContext.parallelize([1, 2, 3, 4, 5])
# Perform a map operation to square each number in the RDD
squared_rdd = rdd.map(lambda x: x**2)
# Filter the squared RDD to keep only even numbers
even_rdd = squared_rdd.filter(lambda x: x % 2 == 0)
# Collect the even numbers as a list
even_list = even_rdd.collect()
# Print the list of even numbers
print(even_list)
# Import SparkSession
from pyspark.sql import SparkSession
# Create a Spark Session
spark = SparkSession.builder.master("local[*]").getOrCreate()
# Create a DataFrame from a CSV file
df = spark.read.csv('mydata.csv', header=True, inferSchema=True)
# Select columns and filter rows
filtered_df = df.select('name', 'age').filter(df['age'] > 30)
# Group the DataFrame by name and calculate the average age
grouped_df = filtered_df.groupBy('name').agg({'age': 'avg'})
# Show the results in the console
grouped_df.show()
# Create a case class for representing a person
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
from pyspark.sql.functions import col
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# Create a Dataset from a list of Person objects
schema = StructType([
StructField("name", StringType()),
StructField("age", IntegerType())
])
people = [Person("Alice", 25), Person("Bob", 30), Person("Charlie", 35)]
ds = spark.createDataFrame(people, schema).as[Person]
# Filter the Dataset to keep only people older than 30
filtered_ds = ds.filter(col("age") > 30)
# Group the Dataset by name and calculate the average age
grouped_ds = filtered_ds.groupBy("name").avg("age")
# Show the results in the console
grouped_ds.show()